FIG2: DOMツリーの再現性
/* 画像内の文字:
- DOMツリー
- テキスト書き出し
- XMLテキスト
- DOMパージング
- X
- A B C */
この記事は、月刊『JavaWorld』誌(IDGジャパン)連載「XMLボキャブラリ の理論と実践」第30回、31回、33回に付属のコラム(本文外)をまとめて、わ ずかに変更したものである。
前回記事において、空白問題について説明した。筆者はこの問題を 「XMLの抜けないトゲ」と表現したが、実際、根が深く一筋縄ではいかない。 今回は、この抜けないトゲとその周辺の状況を仔細に観察してみる。前回が空 白問題の「紹介編」あるいは「導入編」だとすれば、今回は「分析編」である。
筆者の基本的発想は、空白処理と妥当性検証(バリデーション)処理を切り 離すことである。前回述べたように、空白処理と妥当性検証処理はお互いに絡 み合っているのは事実だ。しかし一方、妥当性とはまったく関係ない状況でも、 空白処理が問題になるのである。つまり、空白処理は妥当性検証に従属するわ けではない。この事情を明らかにするために、パージングではなく、その逆の 過程であるDOMツリーのテキストストリームへの書き出しから考察をはじめる。
今、DOMツリーが与えられていて、それをキャラクタ列としてテキストストリー ム(JavaならWriter)に書き出すとする。例として、図FIG1のよう なツリーを考える。これを無造作に書き出すと、長い1行からなるテキストに なってしまう(LIST1)。
| [自己紹介] / \ [挨拶文] [プロフィール] / / | \ (こんにちは。)(わたしは)[名前] (です。) | (花岡美枝子)
<自己紹介><挨拶文>こんにちは。</挨拶文><プロフィール>わたしは<名前>花岡美枝子</名前>です。</プロフィール></自己紹介>
プログラム処理には、長い1行でも何の不都合もないが、人間が読むときには これではたまらない。やはり、リストLIST2のように整形したい。
<自己紹介> <挨拶文> こんにちは。 </挨拶文> <プロフィール> わたしは <名前>花岡美枝子</名前> です。 </プロフィール> </自己紹介>
人間可読性を考慮して書き出すなら、要素ごとに、次のような処理を指定す る必要がある。
このような整形ルールを、合理的かつ簡潔に記述することは興味深い問 題だが、今ここでは言及しない。とりあえず次の2点を心に留めていただきたい。
整形処理と妥当性のあいだに、ゆるく間接的な関係はある。要素の内容モデ ルが、「要素だけの内容」であるか「混合内容」であるかの情報は、整形の方 法を決定するために使える。あまりうるさいことを言わなければ、各要素の内 容モデル種別(「要素だけの内容」か「混合内容」か)だけ分かれば、それな りに整形できる。
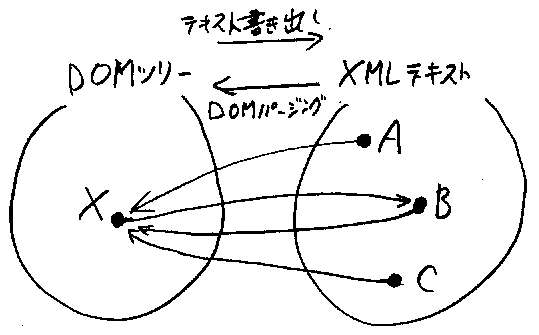
さて、なんらかの整形ルールでDOMツリーをファイル(永続化されたテキスト ストリーム)に書き出したとしよう。そのファイルを再びDOMパーサーを通じ て読み込むと、どうなるだろうか。整形のために余分な空白を追加してしまっ たのだから、同じDOMツリーにはならない。では、読み込むときに(あるいは DOMツリーを作る過程で)、空白を削除するようなパーサーをうまく作れば最 初のDOMツリーを再現できるだろうか。
以上の問題をもう少し厳密に定式化しよう。ある整形ルールRによって、DOM ツリーをテキストストリーム(ファイル)に書き出す機能を、関数TextR で 表す(ルールRをコンストラクタ引数とするDOMシリアライザを考えればよい)。 つまり、DOMツリーXに対して、TextR(X)は対応するXMLテキストを表す。空 白を操作するルールR'に従って、XMLテキストから空白処理したDOMツリーを生 成する関数をTreeR' で表す(ルールR'をコンストラクタ引数とするDOMパー サーを考えればよい)。つまり、XMLテキストAから作られたDOMツリーは TreeR'(A)と書ける。
この設定のもとで、「DOMツリーの書き出しと再読み込みをして、完全に最初 のツリーを再現できる」ということは次のように記述できる(図FIG2も参 照)。
/* 画像内の文字:
これは、TextRとTreeR'が互いに逆写像であることを意味しない。な ぜなら、任意のテキスト形式XML文書Aに対してTextR(TreeR'(A)) = A を要求してないからだ。
これが意味することは、ようするに「行って帰ってきたらもとどおり」とい うことだ。そこで、この形で定式化できる再現可能性をラウンドトリップ (round-trip)性と呼ぶ。
ところで、ラウンドトリップ性を定義するときにイコール記号を使っている。 「もとどおり」とは「前と同じ」ことだから、「同じ」をイコール記号で表し たわけだ。このとき、なにげなく「同じ」「イコール」と言っているが、DOM ツリーの間のイコールとは何だろうか。実は、これは大変に難しい問題だ。と りあえず今は、W3Cで策定されたXMLカノニカライゼーション(*注3)をイコール の定義に利用することにしよう。つまり、「2つのDOMツリーがイコールだと は、カノニカルフォームがまったく“同一”であることだ」とする。こうはいっ ても、カノニカライゼーションの知識がないとピンとこないかも知れないが、 次のように理解しておいて欲しい。
パーザーによっておこなわれる属性値の正規化、DOMツリーにおけるテキスト ノードの正規化と混乱しないように、「正規化」という訳語を使わずにカタカ ナ書きとする。
前節では、イコールの概念(等値性、equality)をXMLカノニカライゼーショ ンを使って定義した。そして、そのイコール概念を使ってラウンドトリップ性 を記述できるのだった。筆者は、空白処理の良し悪しは、ラウンドトリップ性 に基づいて判断されるべきだと思っている。ただし、いま定義したラウンドト リップ性では、空白問題の本質を捉え切れていない。もっと精密化/一般化す る必要がある。その事情を説明しよう。
まず考慮すべきは、「整形ルール(もっと一般的に言えば「無視可能な空白 の入れ方」)は、一通りではない」ということである。改行やインデントは好 みの問題だから、人によって違う。つまり、整形ルールRを1つに固定して、テ キスト書き出し関数 TextR を考えているだけではダメなのだ。多くの場合、複数の整形ルールが 許されるだろうし、無限種類の整形ルールがあるかも知れない。
もう1つの問題は、XMLカノニカライゼーションを使ってイコールを定義した が、このイコールは厳しすぎることだ。そもそもXMLカノニカライゼーション では、「特定の応用を前提とせず、一般的にXMLインスタンスが等しいとは、 どういうことか」を問題にしている。特定応用分野では、カノニカルフォーム が違っていても「同じ」とみなせる場合がある。だから、イコールの定義をもっ とゆるく一般化しておく必要もある。ゆるいイコール関係は(応用分野ごとの) 同値(equivalence)関係と呼ぼう。
前節で、一般化への動機と要求事項を述べた。では、その一般化を遂行して みよう。まずは、なんらかの応用分野を想定する。 そして我々は、次の命題 を仮定したい。
すこし補足説明する。或る応用分野で扱うデータの全体は決まっているはず だ。その対象データをXML表現するわけだ。対象データとその表現であるXMLイ ンスタンスが1:1に対応することは期待できない。そこで、XMLインスタン スXとYが同じ対象データの表現になっているとき、X≡Y として同値関係「≡」 が定まる(*注4)。いま「XMLインスタンス」と言ったが、これはDOMツリーでも XMLテキストでも、どちらでもいい。以下では、XMLインスタンス=DOMツリー の場合だけを考える(そのほうが話が簡単になる)。
XMLインスタンスにその「意味」または「値」を対応させる関数Valがあって、 「X≡Y ⇔ Val(X) = Val(Y)」と定義できれば非常に明解である。だが、多く の場合、Valをハッキリと記述するのは困難である。むしろ、最初に“一意的 とは限らないXML表現”があり、それにより同値関係「≡」が定まり、最後に 「≡」を使ってValを定義することになる。
応用分野とXMLの全体構造を図示するとLIST3となる。この図のなかで、 「=APP」は、応用分野対象データの等値性(equality)であり、 その等値性から導かれるDOMツリーの同値性(equivalence)を「≡TREE」 で示している(*注5)。
/* 画像内の文字:
手書きの絵では一部書き忘れがあるので、下のテキストを信じてください。
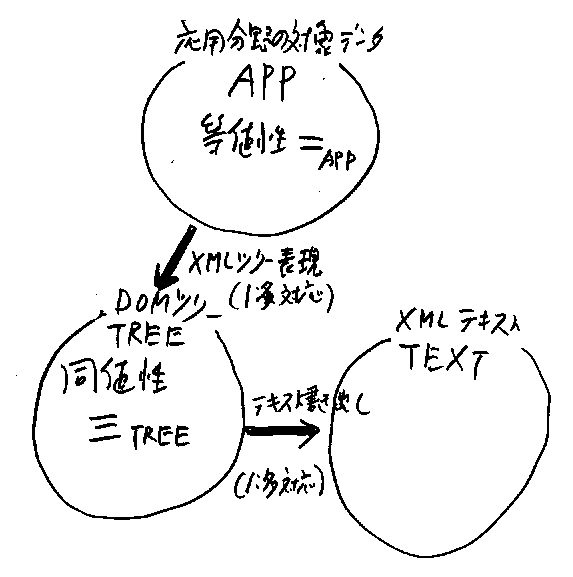
通常、応用分野における対象データの領域APPを明確に定義するのは難しい。 また、対象データがもともとXMLインスタンスであることも多い。だから、図 の中の領域(集合)APP、多値の関数(非決定性写像)XmlTreeを直接相手にす るのは得策ではない。その代わりに、ハッキリと定義できる領域TREEとTEXT、 そして関数Text* (*注6)を議論の対象する。
Text*は、整形ルールRを伴うテキスト書き出しTextR のルールRをいろ いろと変化させた“テキスト書き出しのファミリー”を意味する。{TextR | R ∈Rule} と書けばより正確である。
この文脈のもとで、やっと「正しい空白処理」の定義ができる。テキスト書き出し のための整形ルールの集合Rule={R1, R2, R3, ‥‥(無限かもしれない)}が あるとき、空白処理ルールR'を伴うDOM読み込み(パージング)TreeR'が、 (応用分野の要求に対して)正しい(correct)とは次が成立することである。
ここで重要なことは、絶対的に正しい空白処理なんてものはないことだ。暗 黙に想定される“応用分野の対象データ”の領域があり、それに伴う同値関係 「≡TREE」が定義される。また、整形ルールの集合Ruleも想定する。それ らを使ってはじめてラウンドトリップ性が書き下せる。つまり、空白処理の正 しさは、応用分野と整形ルール達に対して相対的にしか定義できない。
この定義からの帰結をひとつ注意しておこう。整形ルールの集合Ruleが無闇 に大きいと、正しい空白処理R'は存在しないかもしれない。これはつまり、あ まりに勝手な整形用空白の追加を許すと、DOMツリーを再現することが 不可能になることを意味する。今まで我々は、存在しない解を探してい た可能性もある。解(正しい空白処理)の存在は、整形ルールの自由度に依存 するのである。
「たかが空白処理のために、やたらに一般的な状況を設定している」と感じ た読者もいるだろう。だが、「たかが」ではないのだ。「たかが空白処理」な ら、今頃とうに空白問題は解決されているはずだ。十分に一般的な枠組みで考 えないと、何が問題であるかも浮かび上がらないし、空白処理の正しさの基準 も明らかにならない。空白問題にアプローチするなら、「たかが空白」とあな どらず、根本から考え直す必要がある。
ここまでの議論で、空白処理の正しさを判断する枠組みができた。この枠組 みに沿って、次回は現実的な空白処理方式を具体的に組み立ててみよう。