FIG: 弴彉晅偒傾儖僼傽儀僢僩偺椺
/* ordered-alphabet */
楍尵岅偺傾儖僼傽儀僢僩偵弴彉偑擖偭偰偄傞応崌偵丄尵岅偵傕弴彉峔憿傪梌 偊傞偙偲偑偱偒傞丅偨偩偟丄尵岅偺掕媊傪彮偟曄偊偨傎偆偑搒崌偑傛偄丅怴偟 偄乬尵岅偺掕媊乭偺傕偲偱傕丄捠忢偺掕媊偺応崌偲傎偲傫偳摨偠庢傝埖偄偑偱 偒傞丅
宍幃尵岅棟榑偵偍偗傞乬尵岅乭偲偼丄側傫傜偐偺峔暥揑懳徾乮岅丄崁丄暥丄 僣儕乕丄僌儔僼側偳乯偺廤崌偱偁傞(*拲1)丅偦傟偑扨側傞廤崌偱偼側偔偰丄弴 彉峔憿偑擖偭偰偄傞偲偒丄弴彉尵岅偲屇傇(*拲2)丅偮傑傝丄弴彉尵岅偵懏偡傞2偮偺 峔暥揑懳徾偼乮晹暘揑偵乯斾妑壜擻偲側傞丅
偱偼丄峔暥揑懳徾偲偼壗偐丠 偲栤傢傟傞偲尩枾側掕媊偑偁傞傢偗偱偼側偄丅 峔暥揑懳徾偲屇偽傟傞儌僲偑慜傕偭偰偙偺悽偵懚嵼偡傞傢偗偱偼側偄丅側偵偐 傪峔暥揑側懳徾偲傒側偡偺偼変乆偺庡娤偱偁傞丅偮傑傝丄偁傞懳徾傪乽偙傟偼 峔暥揑懳徾偩乿偲巚偄丄偦偺傛偆偵庢傝埖偊偽丄偦傟偼峔暥揑懳徾側偺偱偁傞丅
乽弴彉晅偒尵岅乿偺傎偆偑偄偄偐偲傕巚偭偨丅偑丄"ordered xxx"偺栿岅偼捠 忢乽弴彉亊亊乿偩偐傜丄偦偺廗姷偵廬偭偨丅
婰帠乽愜傟慄偺椺乿偱弎傋偨傛偆側栤戣偵傾僾 儘乕僠偡傞偨傔偵偼丄偳偆偟偰傕弴彉尵岅偺奣擮偑昁梫偦偆偩丅偦偙偱丄偙偺 婰帠偱丄弴彉尵岅偺堦斒揑偐偮婎慴揑側帠崁偵偮偄偰弎傋傞丅
懡偔偺応崌丄傾儖僼傽儀僢僩乮峔暥揑懳徾偺婎杮峔惉慺乯偵傕 偲傕偲弴彉偑擖偭偰偄偰丄偦傟偵傛傝尵岅乮偲屇偽傟傞廤崌乯偺忋偺弴彉峔憿 偑掕媊偝傟傞丅傛偭偰偙偙偱偼丄傾儖僼傽儀僢僩偺弴彉峔憿偐傜摫偐傟偨弴彉 偩偗傪峫偊傞丅
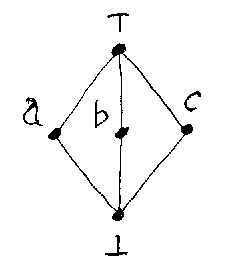
儼偼傾儖僼傽儀僢僩偲偡傞(*拲3)丅儼偵弴彉峔憿偑擖偭偰偄傞偲偒乪弴彉晅 偒傾儖僼傽儀僢僩乫偲屇傇(*拲4)丅弴彉晅偒傾儖僼傽儀僢僩偼丄戜廤崌乮underlying set乯儼偲偦偺忋偺弴彉乮partial order乯亝傪慻偵偟偰(儼丄亝)偲彂偔傋偒偩 偑丄扨偵儼偩偗偱弴彉傕崬傔偨廤崌傪堄枴偡傞偲偡傞丅偮傑傝丄婰崋偺棎梡偩 偑儼=(儼, 亝)丅
暥帤乽儼乿乮僔僌儅乯傪傾儖僼傽儀僢僩傪昞偡偨傔偵巊偆偺偼丄宍幃尵岅棟 榑偺廗姷偱偁傞丅偙偺偰偺廗姷偵丄偨偄偟偨堄枴偑偁傞傢偗偱偼側偄丅偵傕偐 傢傢傜偢丄廬偆傎偆偑柍擄偲偄偊傞丅
傾儞儕儍乕丄偙偭偪偱偼乽弴彉晅偒乿偵側偭偰偄傞丅柍堄幆偩偭偨丄婥偑晅 偐側偐偭偨丅捈偟偨傎偆偑偄偄偐側丠
師偺恾偼丄弴彉晅偒傾儖僼傽儀僢僩偺椺偱偁傞丅
/* ordered-alphabet */
儼偺儊儞僶乕偐傜峔惉偝傟傞楍偺慡懱傪Seq(儼)偲偡傞丅Seq(儼)偺儊儞僶乕丄 偮傑傝楍傪兛丄兝側偳偱昞偡丅1埲忋偺惍悢i偵懳偟偰丄兛i偼丄楍兛偺i斣栚 偵弌尰偡傞儼偺儊儞僶乕偩偲偡傞(*拲5)丅
僀儞僨僢僋僗斣崋傪0偐傜偼偠傔傞偐丄1偐傜偼偠傔傞偐偼丄偄偮偱傕擸傫偱 偟傑偆偑丄偙偺婰帠偱偼1偐傜偺斣崋晅偗偲偡傞丅
儼偵弴彉偑掕媊偝傟偰偄傟偽丄Seq(儼)偵傕弴彉偑擖傞丅偦偺掕媊偼埲壓偺偲 偍傝丅
兛, 兝伕Seq(儼)偩偲偟偰丄兛亝兝偲偼丗
儼傪忋偺恾偺傛偆側弴彉偑擖偭偨廤崌{a, b, c, T, 佦}偩偲偟偰丄偄偔偮偐 偺椺傪嫇偘傞丅
楍偺弴彉偺掕媊偐傜丄length(兛)亗length(兝) 側傜丄 兛偲兝偼斾妑晄擻偱偁傞丅傛偭偰丄偡傋偰偺楍兲偵懳偟偰兲亝兛偲側傞傛 偆側兛乮偮傑傝丄嵟戝尦乯偼懚嵼偟側偄丅摨條偵嵟彫尦傕懚嵼偟側偄丅偨偩偟丄 挿偝n偺楍偺側偐偱偺嵟戝尦乛嵟彫尦偼懚嵼偡傞偐傕偟傟側偄(*拲6)丅
偡傋偰偺楍偵懳偡傞嵟戝尦乛嵟彫尦偑懚嵼偡傞傛偆偵丄掕媊傪庤捈偟偡傞偙 偲偼梕堈偱偁傞偑丄崱偼昁梫偑側偄偐傜峫偊側偄偙偲偵偡傞丅
儼偑弴彉廤崌偺偲偒丄Seq(儼)傕忋偺掕媊偱弴彉廤崌偵側傞丅偮傑傝丄Seq(儼) 忋偵掕媊偝傟偨亝偼師傪枮偨偡丅乮掕媊偐傜偨偩偪偵廬偆丅乯
楍偺楢愙乮concatenation乯偵娭偟偰丄師偑惉棫偡傞(*拲7)丅偙傟傜偺惈 幙傕丄亝偺掕媊偵増偊偽梕堈偵妋擣偱偒傞乮楙廗栤戣乯丅
偮傑傝丄Seq(儼)偼丄楢愙偵娭偟偰弴彉儌僲僀僪偲側傞丅
偙偙偱丄屻偱巊偆搒崌偐傜丄弴彉廤崌偺堦斒榑傪彮偟媍榑偟偰偍偔丅
弴彉廤崌X偺晹暘廤崌A偑師偺忦審傪枮偨偡偲偒丄乪壓曽暵乫乮lower closed乯 偲偄偆丅
慡懱廤崌X偲嬻廤崌O偼柧傜偐偵壓曽暵偱偁傞丅A丄B偑壓曽暵偩偲偡傞偲丄師 偑惉棫偡傞丅
1斣栚傪帵偟偰傒傛偆丅
傛傝堦斒偵丄{Ai | i伕I} 偑壓曽暵側廤崌Ai払偺懓偩偲偟偰丄師偑尵偊 傞丗
崱搙偼2斣栚偩偗帵偟偰傒傞丅
Pow(X)偼X偺晹暘廤崌慡懱偺廤崌乮儀僉廤崌乯丄PowLC(X)傪丄X偺壓曽暵 晹暘廤崌偺慡懱偲偡傞丅PowLC(X) 伜 Pow(X) 偱偁傞丅 崱弎傋偨PowLC(X)偺惈幙偐傜丄Pow(X)偺懇墘嶼傪PowLC(X)偵惂尷偱偒 傞丅偙偺惂尷偟偨墘嶼偵傛傝丄 PowLC(X)偼廤崌懇偵側傞丅
戞2愡偱丄傾儖僼傽儀僢僩儼偑弴彉廤崌側傜丄Seq(儼)傕弴彉廤崌 偵偱偒傞偙偲偑傢偐偭偨丅偙偺偲偒丄儼偺儊儞僶乕傪挿偝1偺楍偲偟偰杽傔崬 傓幨憸 儼仺Seq(儼)偼丄弴彉傪曐偮幨憸偵側偭偰偄傞丅傑偨丄Seq(儼)忋偱楢 愙墘嶼傪峫偊傞偲丄弴彉儌僲僀僪偵側傞偺偩偭偨丅
偝偰丄捠忢偺宍幃尵岅偺掕媊偱偼丄Seq(儼)偺擟堄偺晹暘廤崌傪尵岅偲屇傇偺偩偑丄 偙偺掕媊傪偦偺傑傑嵦梡偡傞偺偼椙偔側偄丅扨側傞Seq(儼)偺晹暘廤崌傪尵岅 偩偲偡傞偲丄榖偑側傔傜偐偵恑傑側偄丅忦審傪晅偗傞偙偲偵偡傞丅
弴彉晅偒傾儖僼傽儀僢僩忋偺尵岅偼丄師偺傛偆偵掕媊偡傞丅
尵岅偼丄乮弴彉廤崌偲峫偊偨乯Seq(儼)偺晹暘廤崌偩偐傜丄Seq(儼)偐傜桿摫 偝傟偨弴彉傪帩偮丅偮傑傝丄忋偱掕媊偟偨尵岅偼弴彉尵岅偱偁傞丅
側偍丄儼偵弴彉偑側偄偲偒丄乬棧嶶弴彉偑偁傞乭偲傒側偟偰儼傪乮摿暿側乯 弴彉廤崌偲峫偊傞偙偲偑偱偒傞丅乮棧嶶弴彉偲偼丄乽x亝y 佁 x=y乿偲偟偰掕 媊偝傟傞弴彉偱偁傞丅乯偦偺偲偒丄忋偺乬尵岅偺掕媊乭偼捠忢偺乬尵岅偺掕媊乭 偵堦抳偡傞丅側偤側傜丄Seq(儼)傕棧嶶弴彉廤崌偵側傞偺偱丄擟堄偺晹暘廤崌 偑壓曽暵偲側傞偐傜偱偁傞丅
弴彉晅偒傾儖僼傽儀僢僩儼偐傜惗惉偝傟傞尵岅偺慡懱傪Lang(儼)偲偡傞丅 Lang(儼) = PowLC(Seq(儼)) 偱偁傞丅戞3愡偺寢壥偐傜丄 Lang(儼)偼廤崌懇偵側傞丅
A偲B偑尵岅偺偲偒丄AB偼A偲B偺楢愙尵岅偩偲偡傞丅乪尵岅偺楢愙乫偺掕媊偼 師偺偲偍傝丅
乬尵岅乭偺掕媊傛傝丄A傕B傕壓曽暵偱偁傞偑丄AB偑壓曽暵偱偁傞偙偲傪帵偝 側偄偲丄忋偺掕媊偼well-defined偱偼側偄丅AB偑壓曽暵偱偁傞偙偲偼師偺傛偆 偵帵偣傞丗 AB偺儊儞僶乕偼丄兛伕A偲兝伕B傪巊偭偰兛兝偺宍偵彂偗傞丅兞亝 兛兝偩偲偟偰丄偙偺兞偑AB偺儊儞僶乕偵側傞偙偲傪帵偣偽傛偄丅亝偺掕媊傛傝丄 兞亝兛兝偱偁傞側傜兞偲兛兝偼挿偝偑摍偟偄丅兞傪乬兛偲摨偠挿偝偺慜敿乭偲 乬兝偲摨偠挿偝偺屻敿乭偵暘偗偰丄兞=兞1兞2偲彂偔丅偡傞偲丄兞1亝兛丄 兞2亝兝偲側傞偑丄A偲B偑壓曽暵偩偭偨偐傜丄兞1伕A丄兞2伕B丅偮傑傝丄 兞偼丄兞1伕A丄兞2伕B偱偁傞兞1丄兞2偵傛傝兞=兞1兞2偲彂偗傞 偺偩偐傜丄AB偺儊儞僶乕偱偁傞丅
偙偙偱丄乽兛1偲兝1偑摨偠挿偝丄兛2偲兝2偑摨偠挿偝偺偲偒丄 兛1兛2亝兝1兝2側傜偽丄兛1亝兛2丄偐偮兝1亝兝2乿偲偄偆惈 幙傪巊偭偰偄傞丅偙傟傕亝偺掕媊偐傜偡偖弌傞惈幙偱偁傞丅
偙傟偱丄Lang(儼)偼丄廤崌懇偱偁傞偲摨帪偵儌僲僀僪偱偁傞偙偲偑暘偐偭偨丅 偝傜偵丄伨偵娭偟偰偼師偺暘攝朄懃偑惉棫偡傞丅
1斣栚偺摍幃偱丄傑偢 A乮伨iBi乯伜 伨i(ABi) 傪帵偦偆丅 A乮伨iBi乯偺儊儞僶乕偼丄兛伕A偲兝伕伨iBi偵傛傝兛兝偲彂偗傞丅偲 偙傠偱兝伕伨iBi偲偼丄揔摉側k伕I偑偁偭偰兝伕Bk偺偙偲偱偁傞偐傜丄 兛兝伕ABk丄傛偭偰丄兛兝伕伨i(ABi)丅
師偵丄媡岦偒偺 伨i(ABi) 伜 A乮伨iBi乯傪帵偦偆丅伨i(ABi)偺 儊儞僶乕偼丄揔摉側k伕I偵懳偟偰ABk偺儊儞僶乕偱偁傞丅偮傑傝丄兛伕A偲兝 伕Bk偵傛傝兛兝偲彂偗傞丅兝伕Bk側傜摉慠偵兝伕伨iBi偩偐傜丄 兛兝伕A(伨iBi)丅
2斣栚傕摨條偵帵偣傞丅
伩偵娭偟偰偼丄A(B伩C) = AB伩AC 偝偊惉棫偟側偄丅 椺偊偽丄A={兠, a}丄B= {兠, a} C={aa}偲偡傞偲丗
偩偑丄A(B伩C) 伜 AB伩AC 偼惉棫偡傞乮楙廗栤戣乯丅
偙偺愡偱偼丄惓婯昞尰偲偦偺夝庍傪梌偊傞丅惓婯昞尰偺峔暥偼捠忢偲傑偭偨 偔摨偠偱偁傞偑丄夝庍偼彮偟曄傢傞丅
嵟弶偵丄惓婯昞尰傪宍幃揑側崁偲偟偰掕媊偡傞丅宍幃揑側掕媊偵娭偟偰偼丄 婰帠乽亀宍幃揑亁偲偼壗偩傠偆乿傪嶲徠丅巊偆 墘嶼婰崋乮娭悢婰崋乯偼丄乽;乿丄乽|乿丄乽*乿偱偁傝丄偦傟偧傟丄楢愙丄崌 暪丄Kleene僗僞乕傪昞偡怱愊傕傝偱偁傞丅
惓婯昞尰偼師偺傛偆偵婣擺揑乮inductive乯偵掕媊偝傟傞丅
椺偊偽丄a, b, c伕儼偩偲偟偰丄(((1 | a);b) | (b;(c*))) 偼惓婯昞尰偱偁 傞丅梋暘側娵妵屖傪徣棯偟偰丄墘嶼巕偺桪愭弴埵偼丄*丄;丄|偺弴偱桪愭偝傟 傞偲寛傔傟偽丄(1 | a);b | b;c* 偲娙棯壔偱偒傞丅埲壓偱偼丄 揔媂娙棯側昞尰傪梡偄傞偙偲偵偡傞丅
惓婯昞尰偺夝庍傪帵偡偨傔偵丄偄偔偮偐偺栺懇傪偡傞丅
兠偼嬻楍偲偟偰丄兠伀 = {兝伕Seq(儼) | 兝亝兠}偼{兠}偱偁傞丅側偤側傜丄 兝亝兠偱偁傞偨傔偵偼丄兝偼挿偝偑0偱側偔偰偼側傜側偄偑丄挿偝0偺楍偼兠埲 奜偵側偄偐傜丅
惓婯昞尰r偵懳偟偰丄偦偺堄枴乮抣乯傪M(r)偲彂偔偙偲偵偡傞丅 偳傫側惓婯昞尰r偵懳偟偰傕M(r)偼尵岅偱偁傞丅
嵟屻偺M(r)*偩偗偼愢柧傪曗懌偟偰偍偔丅擟堄偺尵岅A乮Seq(儼)偺壓曽暵側 晹暘廤崌乯偵懳偟偰丄A* = {兠}伨A伨AA伨AAA伨 ... 偱偁傞丅 偙傟偼丄A0 = {兠}丄A1 = A丄A2 = AA丄乧 偲偟偰丄A* = 伨iAi 乮i=0, 1, 2, ...乯偲傕彂偗傞丅奺Ai偼壓曽暵偩偐傜丄偦傟傜偺崌暪傕壓曽 暵偱偁傞丅傛偭偰丄 A* 傕壓曽暵偱偁傞丅
掕媊偵廬偭偰M((1 | a);b | b;c*)傪寁嶼偟偰傒傞丅偨偩偟丄[a]伀=A丄[b]伀=B丄 [c]伀=C偲偡傞丅
({兠}伨A)B伨BC* 傪偝傜偵寁嶼偡傞偲丗
弴彉晅偒傾儖僼傽儀僢僩偐傜惗惉偝傟傞弴彉尵岅乮偺懓乯傕丄捠忢偺尵岅偲 偦傟傎偳堎側傜側偄偙偲偑傢偐偭偨丅幚嵺丄弴彉傪峫椂偟偰傕丄晧扴偑嬌抂偵 憹偊傞偙偲偼側偄丅堦曽丄弴彉尵岅傪摫擖偡傞偙偲偵傛傝柧傜偐偵側傞尰徾偼 偗偭偙偆懡偄丅偦偺堄枴偱丄弴彉尵岅偼乬偍摼側乭奣擮偱偁傞丅
墳梡椺偼暿側婰帠偱弎傋傞偑丄婰帠乽愜傟慄偺椺乿 偱採帵偟偨栤戣傪夝偔偙偲偼丄1偮偺墳梡椺偵側傞丅